Apache Kafka Principles
Apache Kafka is a high throughput distributed streaming system written in Scala and Java epominously named after the great novelist Franz Kafka. It can be used as a traditional messaging system in favor of JMS or AMQP and allows applications to publish/subscribe to data streams and any events (such as notifications etc) in a decoupled, real-time manner. In this post we’ll cover some key concepts and core architectural aspects of Kafka, along with some practical examples.
Key Concepts
Zookeeper
Zookeeper is a distributed service used in a myriad of use cases, including configuration management, synchronization between services, leader election, message queues, and also as a naming service. Kafka relies on Zookeeper to manage running brokers in a cluster, it does things like electing a new partition leader in case a current partition leader broker goes down.
Starting Zookeeper
$./zookeeper-server-start.sh ../config/zookeeper.properties
Brokers
A broker is a running instance of Kafka, it is identified by a unique numeric id in the cluster which can be changed in the broker.id configuration property.
Starting Kafka
$./kafka-server-start.sh ../config/server.properties
Messages
Messages are one of the main elements in Kafka, they are published into Topics and are basically immutable data consisting of key/value pairs on which the optional key is used to guarantee message ordering. If you specify a key, Kafka deterministically maps your message to a specific partition based on its hash (similar to Rendezvous hashing algorithm), which is very useful if you need to read or replay data at some point in a ordered way.
Topics
A Topic is a logical group, or category on which messages are published, it can be named as something like PUSH_NOTIFICATIONS or driverLocation for instance. By default, Kafka will automatically create a new topic with one partition and a replication factor of 1 when you send a message to a non-existing topic, which might not be desirable in most cases, to disable this behavior you can set the property auto.create.topics.enable to false.
Creating a topic
$./kafka-topics.sh --create --bootstrap-server=localhost:9092 --topic myFirstTopic --partitions=1 --replication-factor=1
–topic specifies the name of our topic, in this case, myFirstTopic;
–bootstrap-server points to running Kafka nodes;
–partitions sets the number of available partitions for our topic;
–replication-factor configures the number of nodes on which our partitions will live, it can’t be higher than the number of available brokers in our cluster.
Partitions
In Kafka every topic has a configurable number of partitions, a partition contains messages from a single topic, it exists inside a broker and can be replicated across the cluster, thus enabling fault tolerance and parallel processing in that it distributes messages across all other nodes. By default messages have a duration of 7 days as seen in the following broker configuration log.retention.hours=168
Offsets
The offset is a sequential number that identifies data location within a single partition.
![Partitions and Offsets described [source]](https://hugoltsp.github.io/images/kafka-architecture-topic-partition-layout-offsets.png)
Partitions and Offsets described [source]
Partition Leaders and In-Sync Replicas (ISR)
Every partition has one elected broker that works as the partition leader, leaders handle message I/O for a given partition and it replicates written data to in-sync replicas. In-sync replicas follow the partition leader, if the current leader goes down and stops sending heartbeats to Zookeepter its partition leadership is shared and assigned among other eligile ISR’s.
Topic Replication
Now let’s imagine we have 4 brokers in our cluster identified as 111, 222, 333 and 444 respectively, and we have created a topic named REPLICATED_TOPIC which is very similar to myFirstTopic, except it has 4 partitions and a replication factor of 4.
To inspect this topic and find out more details about it we can run the following command:
$./kafka-topics.sh --bootstrap-server=localhost:9092 --topic REPLICATED_TOPIC --describe

Replication info on ‘REPLICATED_TOPIC’ topic.
As we can see in this image, each one of our partitions has a broker assigned as leader, partition 3 for instance has broker 111 as it’s leader. Now lets shutdown broker 111 and see what happens.

Partition 3 has a new leader.
Partition 3 leadership has been assigned to broker 333, and it now leads two partitions.
Core APIs
Producer API
Producer API is responsible to send data to topics and specific partitions through message keys, getting to choose the right key is very important to consistently maintain message ordering.
Acknowledgement
–acks=1 This is the default configuration, records will be considered successfully sent when the partition leader receives them.
–acks=-1 Records will be considered successfully sent when the partition leader receives the data and replicates it across all other replicas. This configuration offers the best delivery guarantee, as it waits for the full set of replicas to receive the record.
–acks=0 When set to zero the producer won’t wait for any acknowledgment from brokers at all, which means the message will be considered sent as soon as it has been dispatched by the Producer API, this configuration might be insteresting in cases where you are concerned about performance and can afford to lose some data in the process.
CLI Producer
$./kafka-console-producer.sh --broker-list localhost:9092 --topic HELLO-WORLD --request-required-acks 1
Java Producer
Simple Java Producer using Spring.
public <T> void send(String topic, String key, T payload) {
kafkaTemplate.send(topic, key, payload)
.addCallback(this::onSuccess, this::onFailure);
}
private <T> void onSuccess(SendResult<String, T> result) {
var recordMetadata = result.getRecordMetadata();
var producerRecord = result.getProducerRecord();
log.info("Successfully sent data: [{}] to topic: [{}] | partition: [{}] | offset: [{}]", producerRecord.value(),
recordMetadata.topic(),
recordMetadata.partition(),
recordMetadata.offset());
}
private void onFailure(Throwable t) {
log.error("Error", t);
}
Consumer API
A Consumer is used to read data from a single topic, it reads data in parallel acording to the number of partitions.
Consumers are organized in Consumer Groups, every group has assigned one or more partitions to the topic the consumer subscribed to, in this way consumers from a group can consume messages only from their designated partitions. In Kafka when a message is consumed it is not removed, instead the consumer mantains the offset of the records it has already read through a special Topic called __consumer_offsets which stores info about commited offsets from topics and partitions per consumer group.
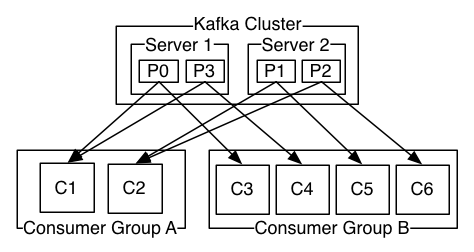
CLI Consumer
$./kafka-console-consumer.sh --bootstrap-server=localhost:9092 --topic=CHARACTERS
Running this command might result in an output like this.
Java Consumer
@KafkaListener(topics = "CHARACTERS")
public void consume(ConsumerRecord<String, ?> record) {
log.info("Received Data [{}]", record.value());
}
//... manually commiting records
@KafkaListener(topics = "E-SPORTS")
public void onMessage(ConsumerRecord<String, String> data, Acknowledgment acknowledgment) {
var game = data.value();
if (shouldAcknowledge(game)) {
log.info(game);
acknowledgment.acknowledge();
} else {
log.info("Not acknowledged: {}", game);
}
}
Source code from this post can be found in Github.